敏感词过滤方案总结
敏感词过滤是内容安全的核心环节。无论是社交媒体、电商平台、在线游戏,还是如今的 AI 应用,都需要对输入和生成的内容进行实时过滤,防止色情、暴力、仇恨言论等违规信息传播。
从技术角度看,敏感词过滤本质上是多模式字符串匹配问题:在一段文本中同时查找多个关键词。
这篇文章接近 2 万字,我会从算法演进开始讲起,还会分享一些生产经验例如对抗变形词、高并发优化、词库管理。
核心结论:
| 算法 | 适用场景 | 特点 |
|---|---|---|
| Trie 树 | 词库规模较小(< 1 万) | 实现简单,易于理解 |
| AC 自动机 | 高吞吐量场景 | 单次扫描匹配所有词,性能最优 |
| 双数组 Trie(DAT) | 大规模词库(> 1 万) | 内存占用低,构建成本高 |
算法演进
下面按从简单到复杂的顺序,逐步介绍各类敏感词过滤算法,看看每一步优化的动机和效果。
暴力匹配(BF 算法)
暴力匹配(Brute Force) 是最直观的方案:遍历文本的每个位置,尝试用每个敏感词进行匹配。
假设敏感词库有 n 个词,平均长度为 m,待匹配文本长度为 L:
public List<String> bruteForceMatch(String text, List<String> words) {
List<String> result = new ArrayList<>();
for (String word : words) { // O(n):遍历每个敏感词
if (text.contains(word)) { // O(L × m):朴素子串匹配
result.add(word);
}
}
return result;
}时间复杂度:O(n × L × m)
| 场景 | 敏感词数 | 文本长度 | 平均词长 | 操作次数 |
|---|---|---|---|---|
| 小规模 | 100 | 1000 | 5 | 50 万 |
| 中规模 | 1000 | 5000 | 5 | 2500 万 |
| 大规模 | 10000 | 10000 | 5 | 5 亿 |
问题分析:
- 重复扫描:每个敏感词都要遍历整段文本,大量字符被重复比较。
- 无状态复用:敏感词之间没有关联,无法利用已匹配的信息。
- 扩展性差:词库增长时性能线性下降。
当词库达到万级别时,暴力匹配的延迟会达到秒级,完全无法满足线上服务的性能要求。
Trie 树:利用前缀减少比较
Trie 树(发音为 /ˈtraɪ/)也称为字典树、前缀树,通过空间换时间的策略优化暴力匹配。核心思想是:利用字符串的公共前缀来减少存储空间和查询时间的开销。
浏览器搜索框的关键词提示功能就可以基于 Trie 树实现:

基本性质
Trie 树具有以下 3 个基本性质:
- 根节点不包含字符,除根节点外每一个节点只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
结构示例
假设敏感词库中有以下词汇:
- 高清视频
- 高清 CV
- 东京冷
- 东京热
构造的 Trie 树结构如下(红色节点表示字符串终止):
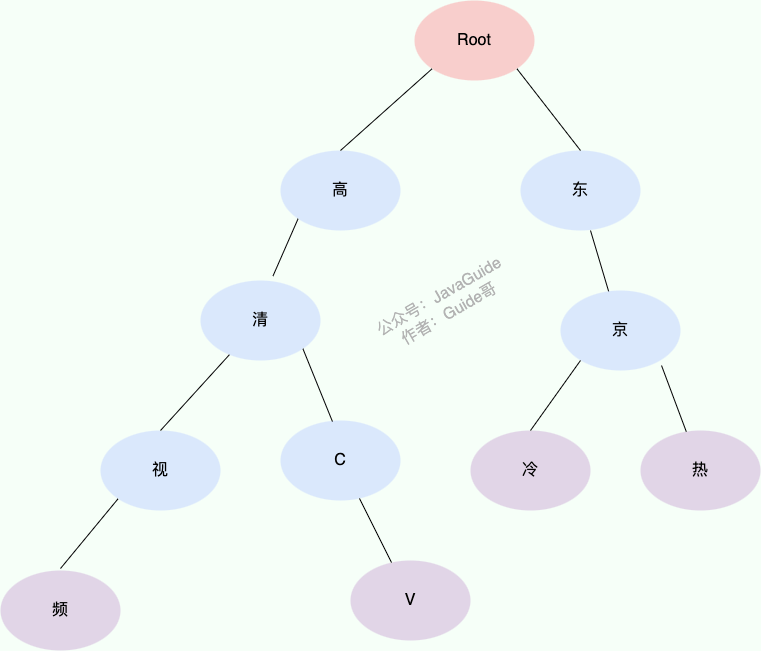
当查找字符串“东京热”时,将其拆分为单个字符“东”、“京”、“热”,然后从根节点逐层匹配。
与暴力匹配的对比
假设词库为 ["she", "he", "his", "hers"],在文本 "ushers" 中查找:
| 算法 | 匹配过程 | 字符比较次数 |
|---|---|---|
| 暴力匹配 | 分别用 4 个词扫描文本 | 约 24 次¹ |
| Trie 树 | 从每个位置开始,沿树匹配 | 约 10 次 |
¹ 此处为简化估算(词数 × 文本长度),实际最坏比较次数取决于每个词的长度与文本位置,会更高。
Trie 树的优势在于:所有敏感词共享同一棵树,一次遍历就能尝试匹配所有词。
复杂度分析
| 指标 | HashMap 实现 | 数组实现 |
|---|---|---|
| 预处理 | O(n × m) | O(n × m × σ) |
| 查询时间 | O(L × m) | O(L × m) |
| 空间复杂度 | O(n × m) | O(n × m × σ) |
σ 为字符集大小(汉字约 2 万,ASCII 仅 128)。本文代码示例采用
HashMap实现,适合中文等大字符集;数组实现适合小字符集(如纯英文)。
代码示例
public class SimpleTrie {
private static class Node {
Map<Character, Node> children = new HashMap<>();
boolean isEnd;
}
private final Node root = new Node();
// 添加敏感词
public void addWord(String word) {
Node node = root;
for (char c : word.toCharArray()) {
node = node.children.computeIfAbsent(c, k -> new Node());
}
node.isEnd = true;
}
// 检测文本中是否包含敏感词
public boolean contains(String text) {
for (int i = 0; i < text.length(); i++) {
Node node = root;
for (int j = i; j < text.length(); j++) {
node = node.children.get(text.charAt(j));
if (node == null) break;
if (node.isEnd) return true;
}
}
return false;
}
// 获取文本中所有匹配的敏感词
public List<String> matchAll(String text) {
List<String> result = new ArrayList<>();
for (int i = 0; i < text.length(); i++) {
Node node = root;
for (int j = i; j < text.length(); j++) {
node = node.children.get(text.charAt(j));
if (node == null) break;
if (node.isEnd) {
result.add(text.substring(i, j + 1));
}
}
}
return result;
}
}Trie 树的局限性
虽然 Trie 树相比暴力匹配有显著提升,但仍存在回溯问题:
在文本 "ushers" 中查找词库 ["she", "he", "his"]:
- 从位置 1 开始,匹配
"s" → "h" → "e",找到"she" - 匹配完成后,回到位置 2,重新匹配
"h" → "e",找到"he"
这种“匹配失败后回退到下一位置重新开始”的策略,在最坏情况下(如文本 "aaaaaaaa" 匹配词 "aaaaab")会退化到 O(L × m)。
能否做到完全不回溯?这就引出了 AC 自动机。
注意:Apache Commons Collections 提供的 PatriciaTrie 是基于位操作的压缩二进制 Trie(PATRICIA = Practical Algorithm To Retrieve Information Coded In Alphanumeric),与本文描述的字符级 Trie 原理不同,不适合直接用于中文敏感词过滤场景。
AC 自动机:单次扫描匹配所有词
AC 自动机(Aho-Corasick Automaton) 是一种建立在 Trie 树之上的多模式匹配算法,由贝尔实验室的 Alfred V. Aho 和 Margaret J. Corasick 于 1975 年提出。
其核心思想与 KMP 算法一脉相承:利用已匹配的信息,在失配时跳转到合适位置继续匹配,避免回溯。区别在于 KMP 处理单模式串,而 AC 自动机处理多模式串。
核心组件
AC 自动机的运行依赖于三个核心函数:
| 函数 | 作用 |
|---|---|
| goto 函数 | 状态转移:从当前状态读入字符后跳转到哪个状态 |
| failure 函数 | 失配跳转:失配时跳转到「最长相同后缀」状态,避免回溯 |
| output 函数 | 输出匹配:记录每个状态对应的匹配词集合 |
构建步骤
AC 自动机的构建分为三步:
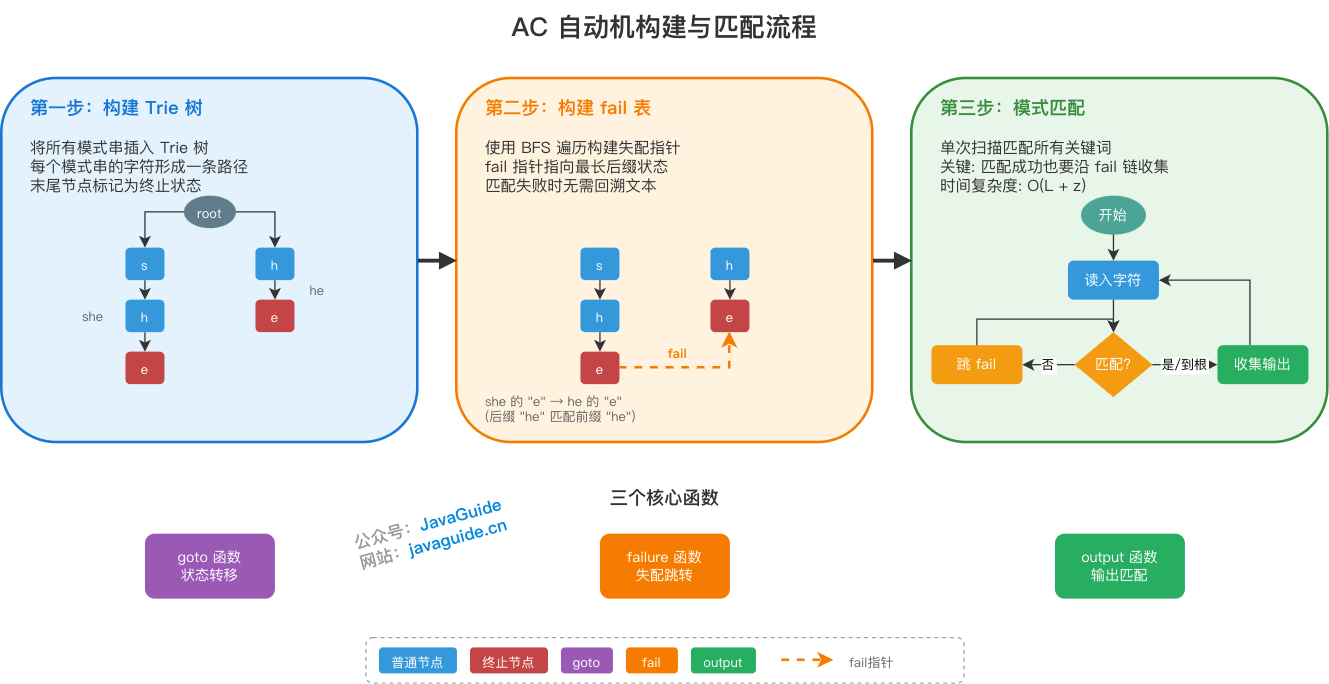
第一步:构建 Trie 树
将所有模式串插入 Trie 树,形成自动机的基础骨架。每个模式串的末尾节点打上终止标记。
第二步:构建 fail 指针(核心)
fail 指针是 AC 自动机的核心机制。它的作用是:当当前字符无法继续匹配时,跳转到哪个状态继续尝试,而不是回到起点。
构建过程使用 BFS(广度优先搜索)逐层遍历,对于当前节点 temp:
- 找到
temp父节点的 fail 节点 - 在该 fail 节点的子节点中寻找与
temp字符相同的节点 - 若存在,则
temp.fail指向该子节点 - 若不存在,继续找 fail 节点的 fail 节点,直到找到或到达 root
fail 指针的本质:指向当前状态对应字符串的最长后缀所在的状态。
与 KMP 的关系
fail 指针就是 KMP 算法中 next 数组在 Trie 树上的泛化。例如:"she" 的后缀 "he" 与 "he" 的前缀相同,因此 "she" 结尾的 'e' 的 fail 指针指向 "he" 中的 'e'。
第三步:模式匹配
从文本串头部开始扫描,指针 p 初始指向 root:
- 状态转移:若当前字符在
p的子节点中,p下移;否则沿 fail 链回退,直到能匹配或回到 root - 收集输出:【关键】每次转移后,必须沿 fail 链遍历一次,收集所有终止状态的匹配词
为什么要沿 fail 链遍历?因为一个长词的后缀可能是另一个短词。例如 "she" 匹配成功时,沿 fail 链可以找到 "he",否则会漏掉嵌套词。
代码示例
public class AhoCorasickAutomaton {
private static class Node {
Map<Character, Node> children = new HashMap<>();
Node fail; // 失配指针
List<String> outputs = new ArrayList<>(); // 该状态对应的匹配词
}
private final Node root = new Node();
// 第一步:构建 Trie 树
public void addWord(String word) {
Node node = root;
for (char c : word.toCharArray()) {
node = node.children.computeIfAbsent(c, k -> new Node());
}
node.outputs.add(word); // 末尾节点记录匹配词
}
// 第二步:构建 fail 指针(BFS)
public void buildFailPointer() {
Queue<Node> queue = new LinkedList<>();
root.fail = root;
// 根节点的直接子节点,fail 指向根
for (Node child : root.children.values()) {
child.fail = root;
queue.offer(child);
}
while (!queue.isEmpty()) {
Node current = queue.poll();
for (Map.Entry<Character, Node> entry : current.children.entrySet()) {
char c = entry.getKey();
Node child = entry.getValue();
// 沿父节点的 fail 链查找是否有字符 c 的转移
Node fail = current.fail;
while (fail != root && !fail.children.containsKey(c)) {
fail = fail.fail;
}
child.fail = fail.children.getOrDefault(c, root);
// 避免自环:如果 fail 指向了自己,改为指向根
if (child.fail == child) {
child.fail = root;
}
// 合并 fail 节点的输出(关键!)
child.outputs.addAll(child.fail.outputs);
queue.offer(child);
}
}
}
// 第三步:模式匹配(单次扫描)
public List<String> match(String text) {
List<String> result = new ArrayList<>();
Node state = root;
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
// 沿 fail 链找到能处理字符 c 的状态
while (state != root && !state.children.containsKey(c)) {
state = state.fail;
}
state = state.children.getOrDefault(c, root);
// 收集当前状态的所有匹配词(已通过 fail 链合并)
result.addAll(state.outputs);
}
return result;
}
}使用示例:
AhoCorasickAutomaton ac = new AhoCorasickAutomaton();
ac.addWord("she");
ac.addWord("he");
ac.addWord("her");
ac.addWord("hers");
ac.buildFailPointer(); // 插入完所有词后,构建一次 fail 指针
List<String> matches = ac.match("ushers");
// 输出: [she, he, her, hers]性能对比
| 算法 | 预处理 | 匹配时间 | 特点 |
|---|---|---|---|
| 暴力匹配 | O(1) | O(L × n × m) | 每个词单独扫描 |
| Trie 树 | O(n × m) | O(L × m) | 可能回溯 |
| AC 自动机 | O(n × m)¹ | O(L + z) | 单次扫描,z 为所有匹配命中的总次数(含重叠匹配)² |
- 使用 HashMap 存储子节点时为 O(n × m);若使用数组存储(需预分配字符集大小 σ),则为 O(n × m × σ)。
- 极端场景下,若词库中存在大量嵌套词(如 "a", "ab", "abc", ..., "abc...z"),z 可能远大于 L,此时耗时由 z 主导。实际工程中敏感词库通常不会出现这种极端嵌套。
AC 自动机实现了线性时间匹配,与敏感词数量无关,只与文本长度和匹配结果数量相关。
将 AC 自动机与 DAT 结合(AhoCorasickDoubleArrayTrie),可以兼顾匹配效率和内存占用。
双数组 Trie(DAT):压缩内存占用
标准 Trie 树内存占用较大(每个节点需要一个 Map),实际工程中通常使用改进版——双数组 Trie(Double-Array Trie,DAT)。
DAT 由日本的 Aoe Jun-ichi 等人在 1989 年的论文《An Efficient Implementation of Trie Structures》中提出。它通过两个整型数组(base[] 和 check[])压缩 Trie 结构:
| 特性 | 标准 Trie(数组实现) | 双数组 Trie |
|---|---|---|
| 空间复杂度 | O(n × m × σ) | O(n × m) |
| 内存占用 | 较大 | 通常可降至数组实现的 20%~30% |
| 实现复杂度 | 简单 | 较复杂(需处理冲突) |
注意:DAT 的压缩效率与词库的公共前缀比例强相关。极端情况下(无公共前缀),压缩效果有限。
参考实现:https://github.com/komiya-atsushi/darts-java
DFA 实现:工程化封装
DFA(Deterministic Finite Automaton,确定性有限自动机) 是自动机理论中的概念。从实现角度看,Trie 从根出发的一次匹配过程本身就是一个 DFA 运行——每个节点代表一个状态,每条边代表一个字符转移。不过,普通 Trie 匹配需要从文本的每个位置重新启动 DFA,而 AC 自动机通过 fail 指针补全了所有状态转移,才是真正的单次扫描多模式 DFA。
Hutool 5.8.x 提供了基于 DFA 的敏感词过滤实现(底层为 Trie):
WordTree wordTree = new WordTree();
wordTree.addWord("大");
wordTree.addWord("大憨憨");
wordTree.addWord("憨憨");
String text = "那人真是个大憨憨!";
// 获得第一个匹配的关键字
String matchStr = wordTree.match(text);
System.out.println(matchStr); // 输出: 大
// matchAll(text, limit, isDensityMatch, isGreedy)
// - limit: 匹配数量上限,-1 表示不限制
// - isDensityMatch: 是否密度匹配(在已匹配词内部继续寻找重叠词)
// - isGreedy: 是否贪婪匹配(true 匹配最长关键词,false 匹配最短关键词)
List<String> matchStrList = wordTree.matchAll(text, -1, false, false);
System.out.println(matchStrList); // 输出: [大, 憨憨]
List<String> matchStrList2 = wordTree.matchAll(text, -1, false, true);
System.out.println(matchStrList2); // 输出: [大, 大憨憨]输出解释:
matchAll(text, -1, false, false):非贪婪 + 非密度匹配- 从位置 0 开始,
"大"匹配成功(最短匹配) - 跳过已匹配字符后,
"憨憨"从位置 2 开始匹配成功 - 结果:
[大, 憨憨]
- 从位置 0 开始,
matchAll(text, -1, false, true):贪婪 + 非密度匹配- 从位置 0 开始,
"大憨憨"匹配成功(最长匹配) - 同时
"大"也匹配成功(作为前缀) - 结果:
[大, 大憨憨]
- 从位置 0 开始,
对抗变形词
实际场景中,用户常通过以下方式绕过敏感词过滤:
| 变形方式 | 示例 | 应对策略 |
|---|---|---|
| 谐音字 | “赌博” → “读博” | 维护谐音词库 |
| 插入符号 | "fuck" → "f*u*c*k" | 预处理去除特殊字符 |
| 繁简混用 | “台灣” → “台湾” | 统一转换为简体后再匹配 |
| 全角字符 | "abc" → "abc" | 全角转半角 |
前置清洗是处理变形词的常用策略:在匹配前对文本进行标准化处理。
public String preprocess(String text) {
StringBuilder sb = new StringBuilder();
for (char c : text.toCharArray()) {
c = toHalfWidth(c); // 全角转半角
c = Character.toLowerCase(c); // 统一小写
if (isChineseOrAlphanumeric(c)) { // 保留中文和字母数字
sb.append(c);
}
}
return toSimplifiedChinese(sb.toString()); // 繁转简
}
private char toHalfWidth(char c) {
if (c >= 'A' && c <= 'Z') return (char) (c - 'A' + 'A');
if (c >= 'a' && c <= 'z') return (char) (c - 'a' + 'a');
if (c >= '0' && c <= '9') return (char) (c - '0' + '0');
return c;
}
private boolean isChineseOrAlphanumeric(char c) {
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z')
|| (c >= '0' && c <= '9') || (c >= '\u4e00' && c <= '\u9fa5');
}ToolGood.Words 等成熟库已内置繁简互换、全角半角转换等功能,可直接使用。
注意
- 位置映射:
preprocess方法会去除特殊字符,导致清洗后的文本与原文位置不再一一对应。如果业务需要返回敏感词在原文中的精确位置(如高亮标注、部分替换),需要维护一张从清洗后位置到原文位置的映射表。 - Unicode 限制:上述代码使用
char遍历字符。Java 的char是 UTF-16 编码单元,BMP 之外的字符(如部分 emoji、汉字扩展区字符)会占用两个char(surrogate pair),逐char遍历会导致这些字符被错误拆分。如果需要支持补充平面字符,应使用codePoints()流处理。
:::
高并发优化
原子热替换:支持词库热更新
生产环境中,敏感词库需要频繁更新,但不能影响正在进行的匹配请求。通过 AtomicReference 实现原子热替换(Atomic Hot-Swap):先在后台构建新 Trie,构建完成后原子替换旧实例,确保读线程不受影响。
public class SensitiveWordFilter {
private final AtomicReference<SimpleTrie> trieRef;
public SensitiveWordFilter(List<String> initialWords) {
this.trieRef = new AtomicReference<>(buildTrie(initialWords));
}
// 匹配时获取当前 Trie
public List<String> match(String text) {
SimpleTrie trie = trieRef.get();
return trie != null ? trie.matchAll(text) : Collections.emptyList();
}
// 更新词库:先构建新 Trie,再原子发布
public void refreshWords(List<String> newWords) {
SimpleTrie newTrie = buildTrie(newWords);
trieRef.set(newTrie); // 原子发布,对读线程立即可见
}
private SimpleTrie buildTrie(List<String> words) {
SimpleTrie trie = new SimpleTrie();
for (String word : words) {
trie.addWord(word);
}
return trie;
}
}关键点:
- 使用
AtomicReference确保切换操作是原子的。 - 旧 Trie 可能仍有线程在使用,依赖 GC 自动回收。
- 可在后台异步构建新 Trie,不影响服务响应。
并行处理:超长文本分段
对于超长文本(如文章、评论),可以分段后并行处理。
注意:分段时必须加入重叠区域,否则会遗漏跨边界的敏感词。
// 使用独立线程池,避免占用 ForkJoinPool.commonPool()
private final ExecutorService filterExecutor =
new ThreadPoolExecutor(
4, 8, 60L, TimeUnit.SECONDS,
LinkedBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy() // 队列满时由调用线程执行,实现背压
);
public List<String> parallelMatch(String text, int chunkSize, int maxWordLength) {
// 重叠区域 = 最长敏感词长度 - 1,防止跨边界漏词
int overlap = maxWordLength - 1;
List<CompletableFuture<List<String>>> futures = new ArrayList<>();
for (int i = 0; i < text.length(); i += chunkSize) {
int start = i;
int end = Math.min(i + chunkSize + overlap, text.length());
String chunk = text.substring(start, end);
// 显式传入自定义线程池
futures.add(CompletableFuture.supplyAsync(() ->
trieRef.get().matchAll(chunk), filterExecutor
));
}
return futures.stream()
.flatMap(f -> f.join().stream())
.distinct()
.collect(Collectors.toList());
}为什么需要重叠区域?
假设敏感词 "赌博网站" 长度为 4,分块大小为 100。若文本恰好从位置 99 开始出现该词,会被切分到两个 chunk:
- chunk1:
...文本结束于位置99赌 - chunk2:
博网站继续...
两个 chunk 都无法匹配完整的 "赌博网站",导致漏报。重叠区域确保每个敏感词都能在至少一个 chunk 中完整出现。
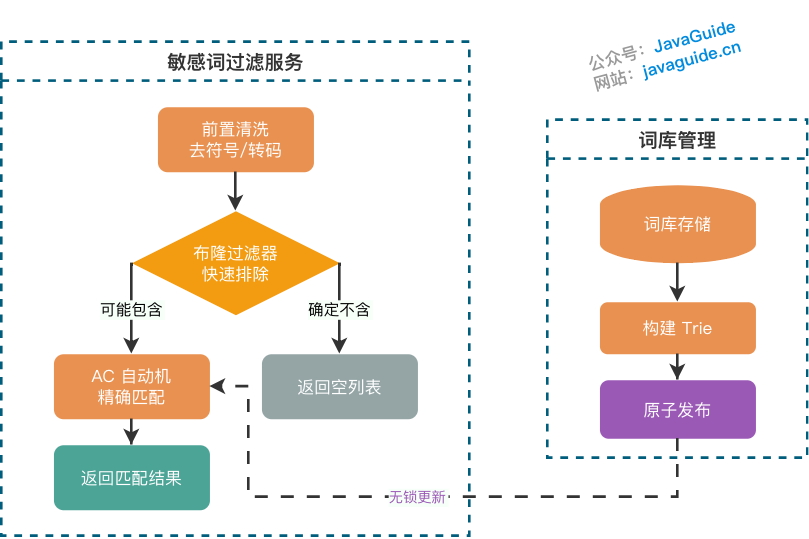
快速排除:布隆过滤器
使用布隆过滤器(Bloom Filter) 做初筛,可以快速排除不含敏感词的文本。
适用前提:该方案仅在绝大多数文本不含敏感词且布隆过滤器假阳性率极低时有收益。因为 quickCheck 本身的复杂度为 O(L × maxWordLen),与 Trie 匹配同阶,如果文本频繁命中布隆过滤器(假阳性),反而会增加额外开销。
注意:布隆过滤器检测的是单个元素的集合成员关系,需要对文本的子串进行检测,而非整段文本。
public List<String> matchWithBloomFilter(String text, int maxWordLength) {
// 快速检测:扫描所有可能的子串
if (!quickCheck(text, maxWordLength)) {
return Collections.emptyList(); // 确定不包含敏感词
}
// 可能包含敏感词,进行精确匹配
return trieRef.get().matchAll(text);
}
private boolean quickCheck(String text, int maxWordLen) {
BloomFilter<String> filter = getBloomFilter(); // 包含所有敏感词的布隆过滤器
for (int i = 0; i < text.length(); i++) {
for (int len = 1; len <= maxWordLen && i + len <= text.length(); len++) {
if (filter.mightContain(text.substring(i, i + len))) {
return true; // 可能包含,需精确匹配
}
}
}
return false; // 确定不包含
}适用场景:敏感词覆盖率较低时,布隆过滤器可以快速排除大量不含敏感词的文本,减少 Trie 匹配次数。但布隆过滤器的扫描本身也有开销(O(L × maxWordLen)),需根据实际数据特征评估是否启用。
开源项目
| 项目 | 语言 | 最低 JDK | 特点 | 适用场景 |
|---|---|---|---|---|
| ToolGood.Words | C#/Java/Python/Go/JS | Java 8+ | 多语言支持,内置繁简互换、全角半角、拼音转换;C# 版本过滤速度超 3 亿字符/秒 | 多语言项目 |
| Hutool DFA | Java | Java 8+ | 轻量级,API 简洁,基于 Trie 实现 | 中小规模词库 |
| AhoCorasickDoubleArrayTrie | Java | Java 7+ | AC 自动机 + 双数组 Trie,性能优异 | 大规模词库、高吞吐量 |
生产建议
词库管理
- 定期更新:敏感词库需要持续维护,支持热加载避免重启服务。
- 分级管理:按业务场景分为高/中/低敏感度,采用不同的处理策略(直接拦截、人工审核、记录日志)。
- 白名单机制:维护白名单防止误杀。典型场景如敏感词 "XXX" 误杀正常词汇 "XXY"(子串误匹配)、"公安" 误杀 "办公安排" 等。常见应对策略包括白名单词组排除、要求最小匹配长度(如仅匹配完整词而非子串)、上下文窗口判定等。
- 匹配日志:记录匹配结果用于词库优化和误报分析。
异常处理
- 词库加载失败:构建新 Trie 失败时(如 OOM、文件损坏),应保留旧 Trie 不变,记录错误日志并告警。
- 空词库处理:词库为空时应记录 WARN 日志,而非静默放行所有文本。
- 匹配超时:超长文本 + 大词库场景,可设置超时熔断,降级为放行或人工审核。
监控指标
| 指标 | 建议阈值 | 说明 |
|---|---|---|
| 匹配延迟(p99) | < 10ms | 单次过滤耗时 |
| 误报率 | < 1% | 正常内容被误判为敏感词 |
| 漏报率 | 持续监控 | 敏感内容未被识别 |
| 词库命中率 | 按需分析 | 各敏感词的触发频率,用于词库优化 |
架构建议
参考资料
学术论文
- Aho, A.V. and Corasick, M.J. (1975). "Efficient string matching: An aid to bibliographic search." Communications of the ACM, 18(6), 333-340.(AC 自动机原始论文)
- Aoe, J., Morimoto, K., and Sato, T. (1989). "An Efficient Implementation of Trie Structures." Software: Practice and Experience.
相关专利
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。