系统需要对用户输入的文本进行敏感词过滤,如色情、政治、暴力相关的词汇。
敏感词过滤本质上是多模式字符串匹配问题:在一段文本中同时查找多个关键词。
核心结论:
| 算法 | 适用场景 | 特点 |
|---|---|---|
| Trie 树 | 词库规模较小(< 1 万) | 实现简单,易于理解 |
| AC 自动机 | 高吞吐量场景 | 单次扫描匹配所有词,性能最优 |
| 双数组 Trie(DAT) | 大规模词库(> 1 万) | 内存占用低,构建成本高 |
2022/1/13大约 14 分钟
系统需要对用户输入的文本进行敏感词过滤,如色情、政治、暴力相关的词汇。
敏感词过滤本质上是多模式字符串匹配问题:在一段文本中同时查找多个关键词。
核心结论:
| 算法 | 适用场景 | 特点 |
|---|---|---|
| Trie 树 | 词库规模较小(< 1 万) | 实现简单,易于理解 |
| AC 自动机 | 高吞吐量场景 | 单次扫描匹配所有词,性能最优 |
| 双数组 Trie(DAT) | 大规模词库(> 1 万) | 内存占用低,构建成本高 |
红黑树(Red Black Tree)是一种自平衡二叉查找树。它是在 1972 年由 Rudolf Bayer 发明的,当时被称为平衡二叉 B 树(symmetric binary B-trees)。后来,在 1978 年被 Leo J. Guibas 和 Robert Sedgewick 修改为如今的“红黑树”。
由于其自平衡的特性,保证了最坏情形下在 O(logn) 时间复杂度内完成查找、增加、删除等操作,性能表现稳定。
在 JDK 中,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
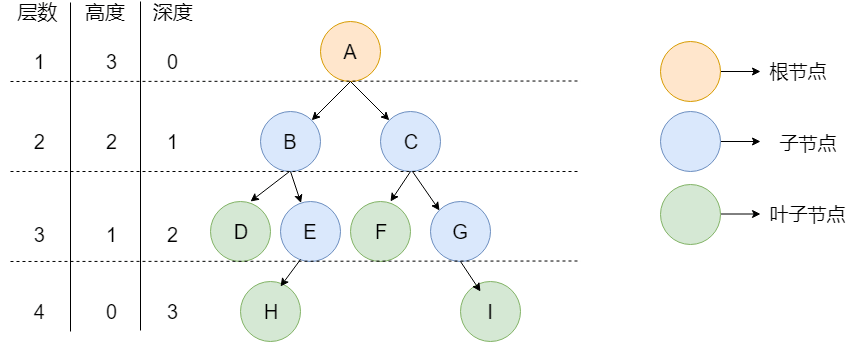
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
一棵树具有以下特点:
下图就是一颗树,并且是一颗二叉树。
堆是一种满足以下条件的树:
堆中的每一个节点值都大于等于(或小于等于)子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。
大家可以把堆(最大堆)理解为一个公司,这个公司很公平,谁能力强谁就当老大,不存在弱的人当老大,老大手底下的人一定不会比他强。这样有助于理解后续堆的操作。
!!!特别提示:
图是一种较为复杂的非线性结构。 为啥说其较为复杂呢?
根据前面的内容,我们知道:
但是,图形结构的元素之间的关系是任意的。
何为图呢? 简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:G(V,E),其中,G 表示一个图,V 表示顶点的集合,E 表示边的集合。
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
数组的特点是:提供随机访问 并且容量有限。
假如数组的长度为 n。
访问:O(1)//访问特定位置的元素
插入:O(n )//最坏的情况发生在插入发生在数组的首部并需要移动所有元素时
删除:O(n)//最坏的情况发生在删除数组的开头发生并需要移动第一元素后面所有的元素时布隆过滤器相信大家没用过的话,也已经听过了。
布隆过滤器主要是为了解决海量数据的存在性问题。对于海量数据中判定某个数据是否存在且容忍轻微误差这一场景(比如缓存穿透、海量数据去重)来说,非常适合。
文章内容概览: